Données spatiales
Données
Le fichier bryo_belg.csv est adapté des données de l’étude:
Neyens, T., Diggle, P.J., Faes, C., Beenaerts, N., Artois, T. et Giorgi, E. (2019) Mapping species richness using opportunistic samples: a case study on ground-floor bryophyte species richness in the Belgian province of Limburg. Scientific Reports 9, 19122. https://doi.org/10.1038/s41598-019-55593-x
Ce tableau de données indique la richesse spécifique des bryophytes au sol (richness) pour différents points d’échantillonnage de la province belge de Limbourg, avec leur position (x, y) en km, en plus de l’information sur la proportion de forêts (forest) et de milieux humides (wetland) dans une cellule de 1 km\(^2\) contenant le point d’échantillonnage.
bryo_belg <- read.csv("../donnees/bryo_belg.csv")
head(bryo_belg)## richness forest wetland x y
## 1 9 0.2556721 0.5036614 228.9516 220.8869
## 2 6 0.6449114 0.1172068 227.6714 219.8613
## 3 5 0.5039905 0.6327003 228.8252 220.1073
## 4 3 0.5987329 0.2432942 229.2775 218.9035
## 5 2 0.7600775 0.1163538 209.2435 215.2414
## 6 10 0.6865434 0.0000000 210.4142 216.5579Ajustement d’un modèle géostatistique
Pour cet exercice, nous utiliserons la racine carrée de la richesse spécifique comme variable réponse. La transformation racine carrée permet souvent d’homogénéiser la variance des données de comptage afin d’y appliquer une régression linéaire.
Note: Pour modéliser directement les données de comptage, par exemple avec une distribution de Poisson, tout en incluant la dépendance spatiale, il faudrait passer par un modèle de vraisemblance personnalisé ou un modèle bayésien.
- Visualisez le patron spatial de la richesse des bryophytes du sol (points de taille différente selon la richesse des espèces). Ensuite, visualisez la relation entre la richesse des bryophytes du sol et le couvert forestier. Calculez la corrélation entre ces variables.
Solution
bryo_belg$sr <- sqrt(bryo_belg$richness)
library(ggplot2)
ggplot(bryo_belg, aes(x = x, y = y, size = sr)) +
geom_point() +
coord_fixed()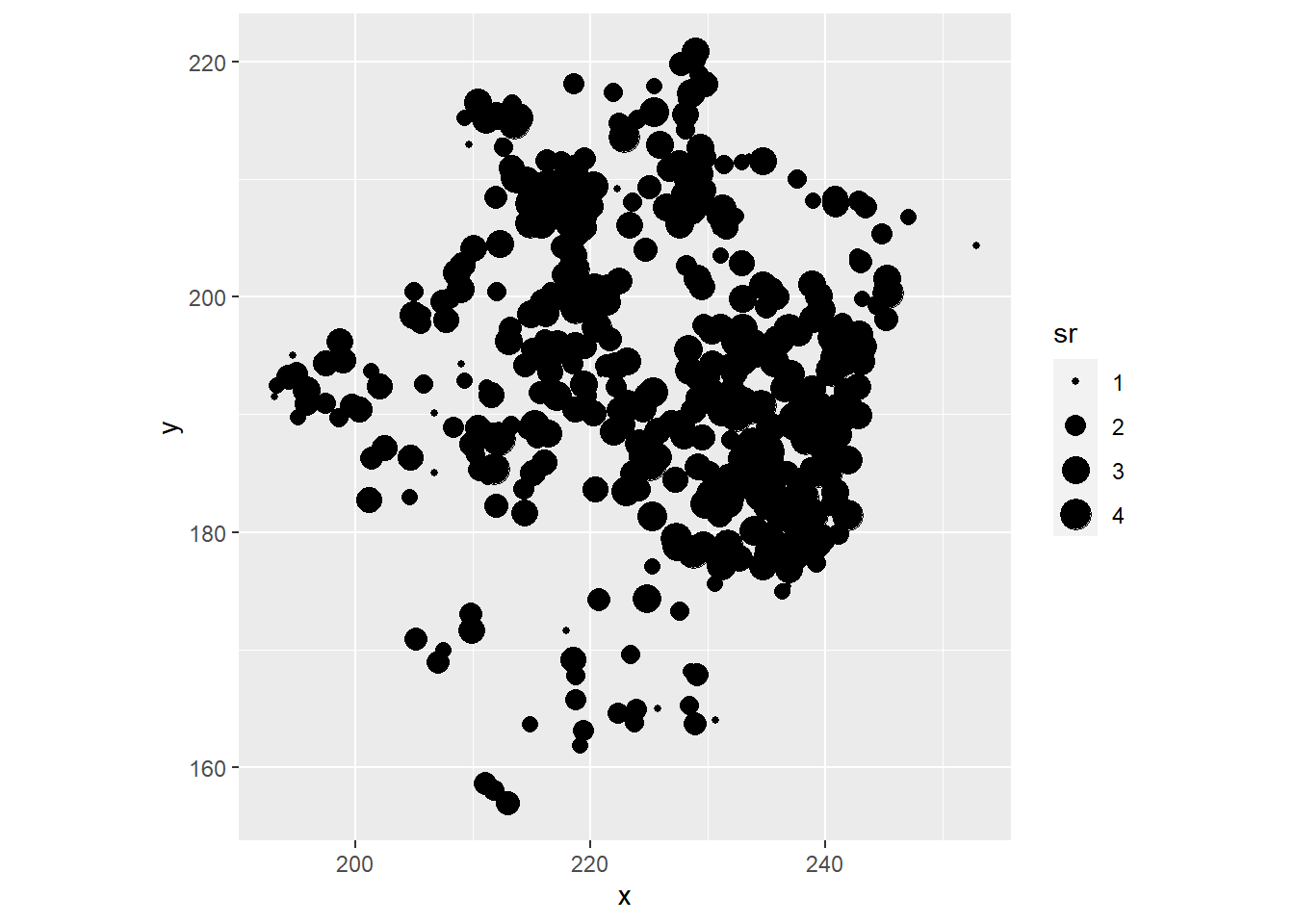
ggplot(bryo_belg, aes(x = forest, y = sr)) +
geom_point()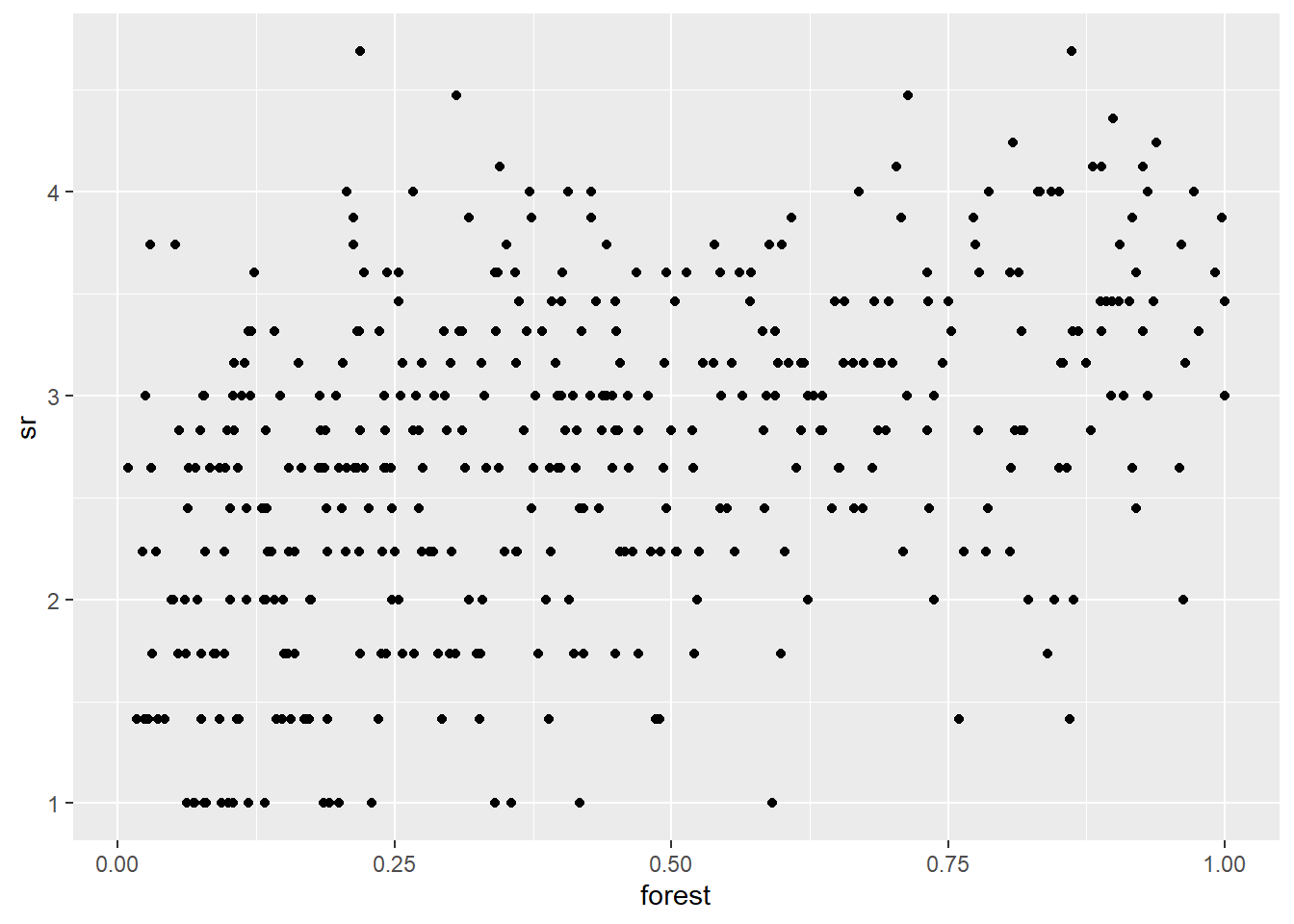
cor(bryo_belg$sr,bryo_belg$forest)## [1] 0.4483081- Ajustez un modèle linéaire de la richesse spécifique transformée en fonction de la fraction de forêt et de milieux humides, sans tenir compte des corrélations spatiales. Quel est l’effet des deux prédicteurs selon ce modèle?
Solution
bryo_lm <- lm(sr ~ forest + wetland, data = bryo_belg)
summary(bryo_lm)##
## Call:
## lm(formula = sr ~ forest + wetland, data = bryo_belg)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.8847 -0.4622 0.0545 0.4974 2.3116
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.34159 0.08369 27.981 < 2e-16 ***
## forest 1.11883 0.13925 8.034 9.74e-15 ***
## wetland -0.59264 0.17216 -3.442 0.000635 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.7095 on 417 degrees of freedom
## Multiple R-squared: 0.2231, Adjusted R-squared: 0.2193
## F-statistic: 59.86 on 2 and 417 DF, p-value: < 2.2e-16Il y a un effet positif de la fraction de forêts et négatif de la fraction de milieux humides; tous deux sont significatifs.
- Calculez le variogramme empirique des résidus du modèle en (b). Semble-t-il y avoir une corrélation spatiale entre les points?
Note: L’argument cutoff de la fonction
variogram spécifie la distance maximale à laquelle le
variogramme est calculé. Vous pouvez ajuster manuellement cette valeur
pour vous assurer que le palier du variogramme soit atteint.
Solution
library(gstat)
vario <- variogram(sr ~ forest + wetland, locations = ~ x + y, data = bryo_belg,
cutoff = 50)
plot(vario)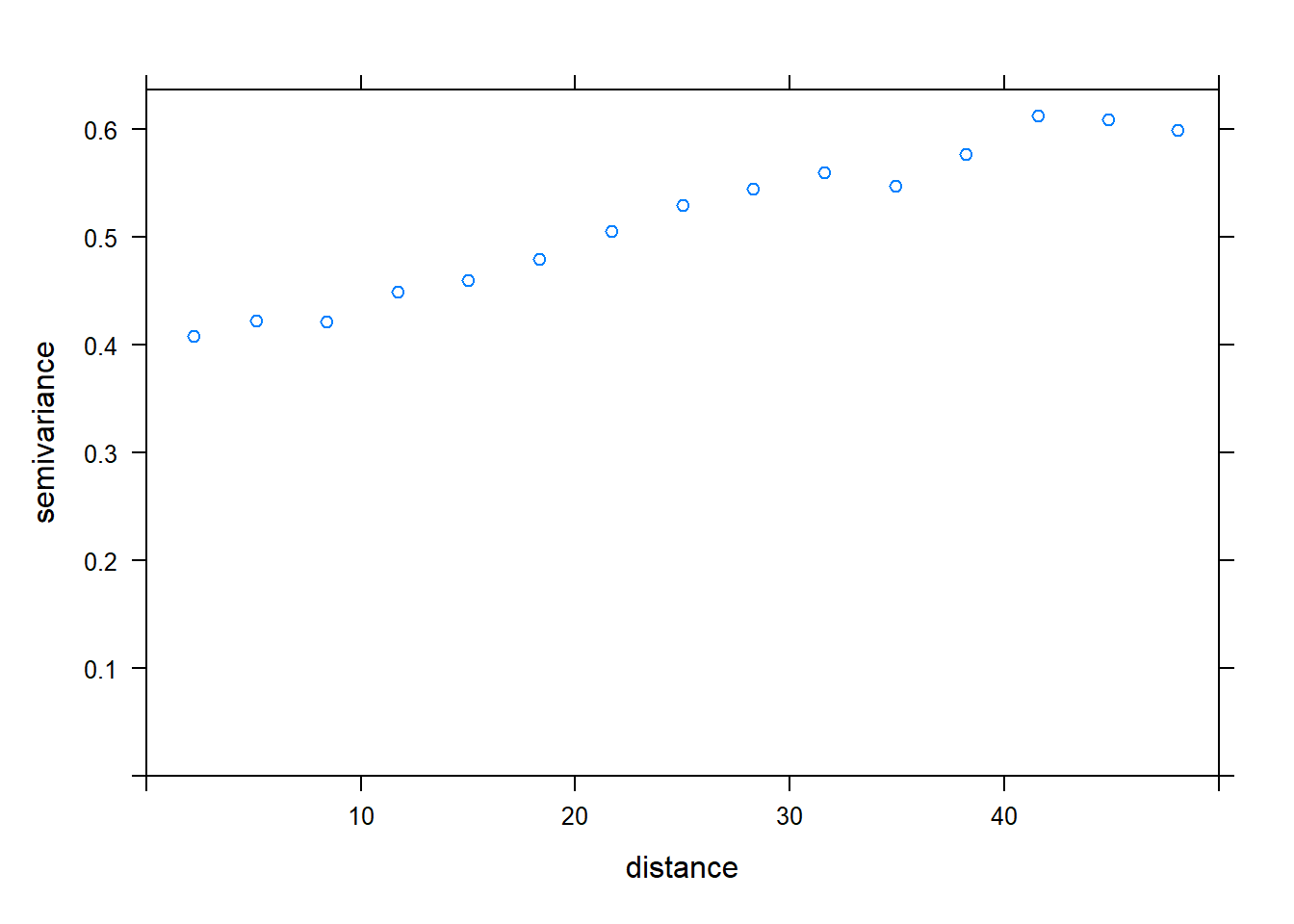
Oui, la variance est plus faible pour de petites distances et semble augmenter jusqu’à environ 40 km.
- Essayez d’ajuster plusieurs modèles paramétriques au variogramme empirique (exponentiel, gaussien, sphérique). Quel est celui sélectionné? Tracez le modèle choisi sur le variogramme empirique.
Solution
vfit <- fit.variogram(vario, vgm(c("Exp", "Gau", "Sph")))
vfit## model psill range
## 1 Nug 0.4083577 0.00000
## 2 Gau 0.1865780 25.19052plot(vario, vfit, col = "black")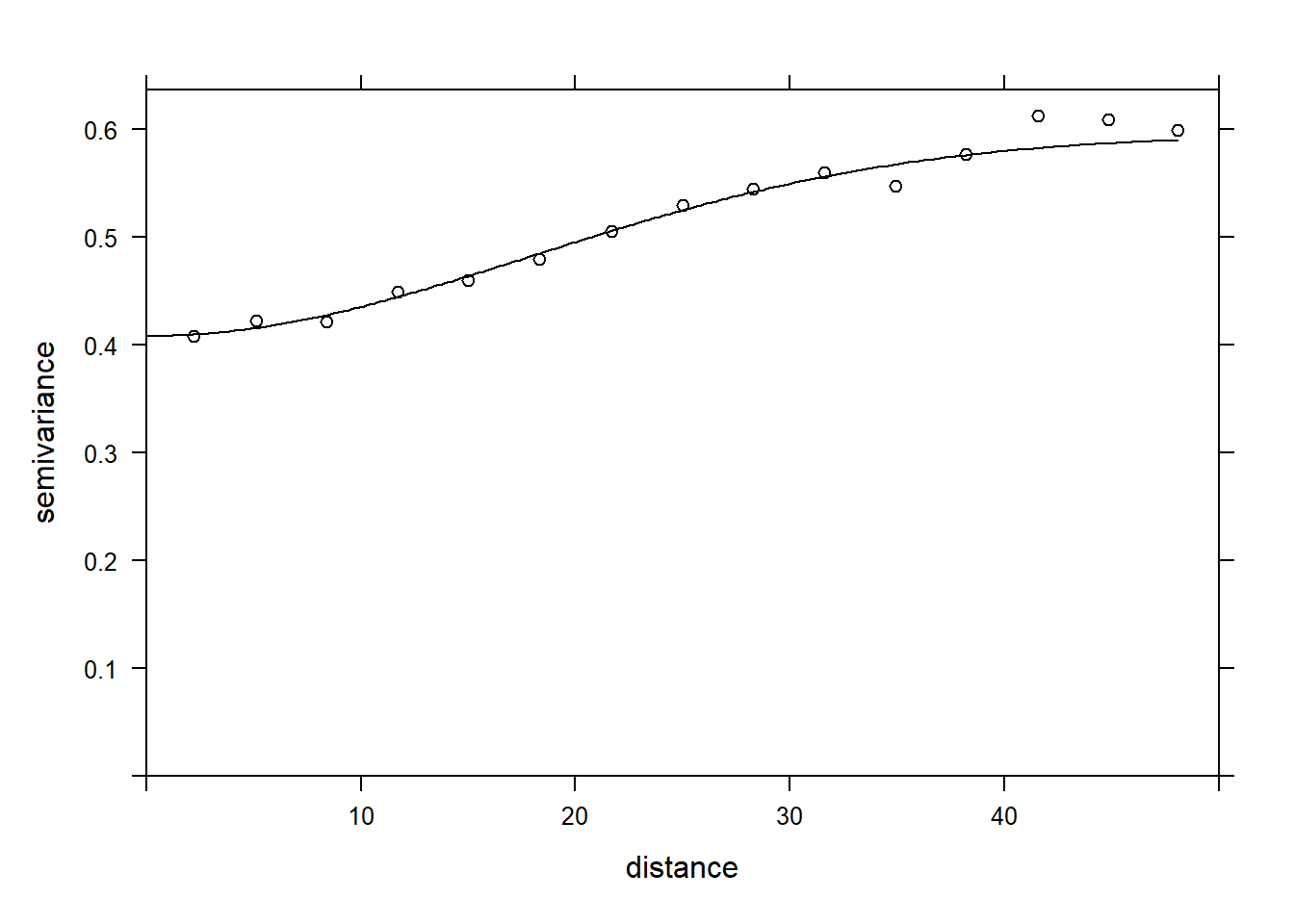
- Ré-ajustez le modèle linéaire en (a) avec la fonction
glsdu package nlme, en essayant différents modèles de corrélation spatiale (exponentiel, Gaussien, sphérique). Comparez les modèles (incluant celui sans corrélation spatiale) avec l’AIC.
Solution
library(nlme)
mod1e_1 <- gls(sr ~ forest + wetland, data = bryo_belg)
mod1e_Gaus <- gls(sr ~ forest + wetland, data = bryo_belg,
correlation = corGaus(form = ~ x + y, nugget = TRUE))
AIC(mod1e_1,mod1e_Gaus)## df AIC
## mod1e_1 4 917.5085
## mod1e_Gaus 6 870.9592Le modèle avec corrélation spatiale a l’AIC le plus faible. Il est préferable.
- Quel est l’effet de la fraction de forêts et de milieux humides selon le meilleur modèle en (c)? Expliquez les différences entre les conclusions de ce modèle et du modèle en (a).
Solution
summary(mod1e_Gaus)## Generalized least squares fit by REML
## Model: sr ~ forest + wetland
## Data: bryo_belg
## AIC BIC logLik
## 870.9592 895.1577 -429.4796
##
## Correlation Structure: Gaussian spatial correlation
## Formula: ~x + y
## Parameter estimate(s):
## range nugget
## 14.7381332 0.7409514
##
## Coefficients:
## Value Std.Error t-value p-value
## (Intercept) 2.1279925 0.1758710 12.099734 0.0000
## forest 0.7052987 0.1456888 4.841134 0.0000
## wetland -0.2276565 0.1802216 -1.263203 0.2072
##
## Correlation:
## (Intr) forest
## forest -0.350
## wetland -0.327 0.245
##
## Standardized residuals:
## Min Q1 Med Q3 Max
## -1.9997519 -0.1987275 0.5301851 1.1031378 3.3177771
##
## Residual standard error: 0.7498226
## Degrees of freedom: 420 total; 417 residualLa magnitude des coefficients est plus faible, leur erreur-type est plus élevée et l’effet des milieux humides n’est plus significatif. En raison des corrélations spatiales, nos différents points ne sont pas indépendants et une partie de l’effet originalement attribué aux variables prédictrices pourrait être une coïncidence due aux corrélations spatiales à la fois de la variable réponse et des variables prédictrices.